Atom编辑器的并发缓冲区实现
Atom是Github开源的一款文本编辑器。包含丰富的扩展包,高度个性定制化。此文来自Atom的官方博客,由[nathansobo]撰写。主要阐述了Atom引入的一种缓冲区实现机制。
标签:atom;buffer;splay tree;
Atom是Github开源的一款文本编辑器。包含丰富的扩展包,高度个性定制化。此文来自Atom的官方博客,由nathansobo撰写。主要阐述了Atom引入的一种缓冲区实现机制。
有几个Atom的功能是基于开放缓冲区中内容的长运算。直到最近,只有运行在JavaScript上的主进程才能访问缓冲区中的文本。这使得很难保证Atom在所有情况下的响应能力,特别是在编辑较大的文件时。
随着Atom 1.19的发布,这种情况发生了变化,通过以C++实现的新的文本存储数据结构打开了大大增加并行性的大门。这种新的设计为性能和可伸缩性提供了许多好处,其中主要功能是工作线程读取之前缓冲区状态的快照而不阻塞主线程写入。
分层变更
Atom的新缓冲区实现的关键思想是将缓冲区的内容分成两个主要状态。首先是基本文本,它与最近从磁盘读取或写入磁盘的文档的版本相对应。基本文本是不可变的,并存储在一个连续分配的内存块中。叠加在基本文本之上的是未保存的更改,这些更改存储在单独的数据结构中,称为Patch。要记录编辑内容,我们只需修改该Patch,而不是将缓冲区的全部内容转移到内存中。
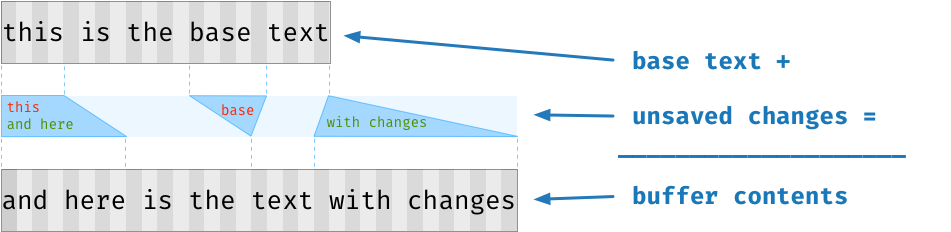
实际上在任何时候都可以有多层Patch。最顶层的Patch总是可变的,但是我们可以通过冻结最上面的Patch并将新的Patch推到堆栈顶部来创建当前缓冲区内容的只读快照。编辑内容修改到这个新的Patch中,直到冻结的快照不再需要为止,此时最上面的Patch可以合并到上一个补丁中。
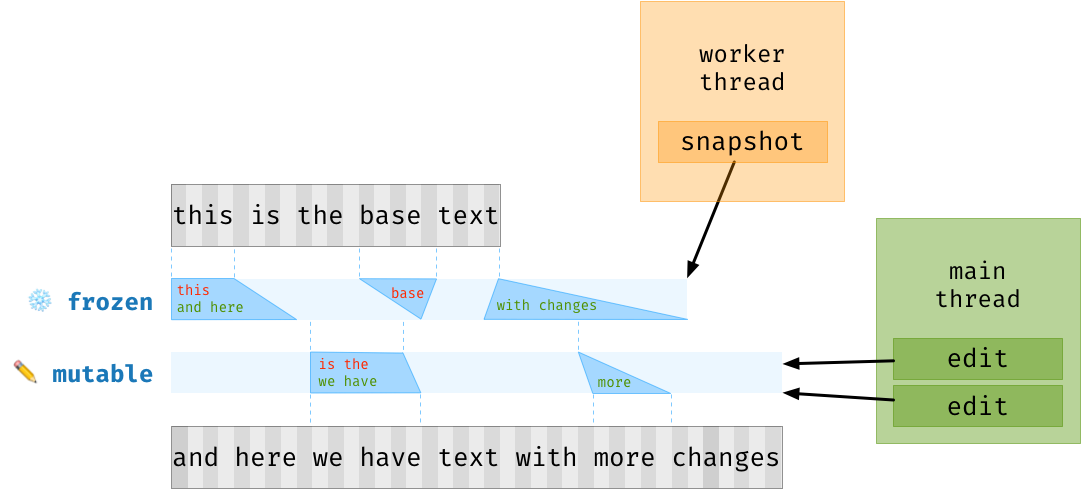
为了读取缓冲区状态,我们遍历连续的chunks,其中每个块对应于来自分层Patch的更改或来自包含基本文本的数组的切片。
下图中红色的
base块是来自基本文本的切片;绿色的more块是来自分层Patch的更改
Patch的数据结构
整个系统的核心是Patch数据结构,它描述了如何将一系列文本变化应用于某些输入以产生新的输出。它包含的信息基本上与通过在输入和输出上运行差异[diff]所获得的信息相同。但它不是通过比较两个缓冲区的内容来构建,而是通过组合一系列编辑来递增构建。
要解决的问题
为了更好地理解补丁解决的问题,请思考以下示例。 我们从一个包含xxxx的缓冲区开始,进行如下操作。
- insert B @ 2 -> xxBxx
- insert C @ 4 -> xxBxCx
- insert A @ 1 -> xAxBxCx
之后,我们需要对我们的变化进行总结,表达为一个像这样的字符差异:
[
{oldRange: [1, 1], oldText: '', newRange: [1, 2], newText: 'A'},
{oldRange: [2, 2], oldText: '', newRange: [3, 4], newText: 'B'},
{oldRange: [3, 3], oldText: '', newRange: [5, 6], newText: 'C'}
]
这个差异中的每个条目都有一个oldRange,它不包含Patch中存在的其他更改。例如,描述C插入的条目具有[3,3]的oldRange,排除了插入A和B的影响。相反,每次变化的newRange反映了所有其他编辑的patch的影响。例如,C的插入有一个[5,6]newRange,其将之前A和B的插入包含在了缓冲中。
如果没有额外的处理,这种汇总是不能从原始编辑流中获得的。思考在索引4处插入C的情况。这个索引已经包含了之前B的插入,但不包含A。A在空间上是C之前插入,但在时间序列上在C之后。为了计算出上面的oldRange和newRange差异,我们需要了解每一个变化的空间关系,而不管他们的时间顺序。
一个简单的解决办法
这个问题的一个简单的解决方案是将每个更改存储在一个列表中,每个更改都存储它的oldText,newText和distanceFromPreviousChange。我们通过遍历现有的变化来确定列表中每个新条目的插入位置。下面是变化列表基于上面的例子的演变。
assert.deepEqual(patch.changes, [])
patch.splice(2, '', 'B')
assert.deepEqual(patch.changes, [
{distanceFromPreviousChange: 2, oldText: '', newText: 'B'}
])
patch.splice(4, '', 'C')
assert.deepEqual(patch.changes, [
{oldText: '', newText: 'B', distanceFromPreviousChange: 2},
{oldText: '', newText: 'C', distanceFromPreviousChange: 1}
])
patch.splice(1, '', 'A')
assert.deepEqual(patch.changes, [
{oldText: '', newText: 'A', distanceFromPreviousChange: 1},
{oldText: '', newText: 'B', distanceFromPreviousChange: 1},
{oldText: '', newText: 'C', distanceFromPreviousChange: 1}
])
在这种情况下,oldText总是空的,因为我们只执行插入操作,但通过使用非空值来表示oldText可以很容易的实现删除或替换。一旦我们有了这个更改列表,我们可以通过迭代列表来产生所需的汇总。
Splay trees
上述方法的问题是,在列表中插入一个变化可能需要我们检查每一个其他变化,这产生了O(n²)的时间复杂度。
为了确保产品性能,我们通过使用splay tree将时间复杂度提高到O(n•log₂n)。Splay树是二叉搜索树的一种,实现相当简单,并且具有"自我优化"的属性。 这意味着,当他们被查询和修改时,他们会自动调整自身结构,以便更方便地访问最近被访问节点附近的节点。对于随机访问,这个属性没有什么帮助,但对于展现高度局部性的工作负载,例如文本编辑器中出现的那些工作负载,这种自我优化行为是非常有用的。
Splay树围绕着一个非常简单的原则。 每次访问一个节点时,都会通过一系列被称为splay的指针旋转来将其旋转到树的根部。 Splaying不仅将节点移动到树的根部,而且还减少了节点附近的树的深度,确保下一次我们访问附近的节点时它将更接近根,因此更快找到。
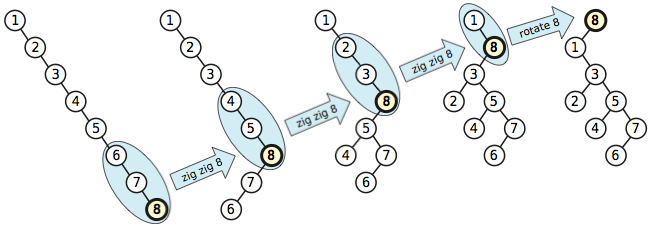
一点需要注意是,这个实现的平均消耗是O(n•log₂n)。 任何单个操作的成本可能高达O(n),但是我们通过重构树来支付任何昂贵的操作,以使后续操作开销更少。任何单一的线性时间操作通常不会导致性能问题。只有当我们开始在一个批次中执行多个线性时间操作时,时间复杂度才是二次的,Splay Tree可以帮助我们避免这种情况。
如果想更多了解[splay trees],可以从David Karger的演讲开始。
在我们的方案中增加Splay Tree
Splay Tree总是呈现为键和值之间的简单有序映射。我们要解决的是一个更复杂的问题:我们的树需要保持新旧坐标空间中每个节点的位置,这样我们就可以有效地更新所有后续插入节点的位置。为此,我们不是将每个节点与一个常量键相关联,而是将每个节点与相对表示的值相关联,这些值表示新老坐标空间中与左侧祖先节点的距离。
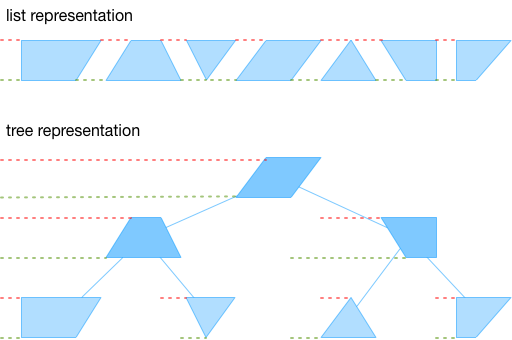
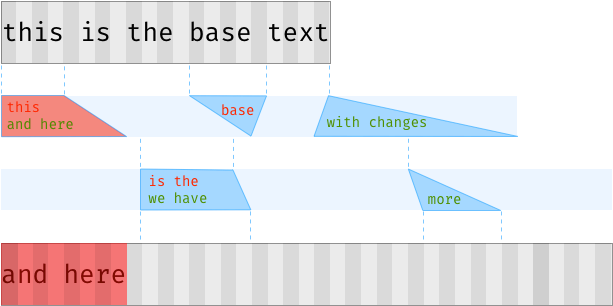
在上图中,每个更改都以梯形图形式显示,表示了替换字符运行的空间影响。 在我们之前说明的列表表示中,与前一个change的距离在两个坐标空间中始终相同,因为任何两个更改之间的文本都保持左侧一致。在树形版本中,每个change存储与其左侧祖先的距离,其汇总了整个子树对该变化左侧的空间影响。上面的每个阴影较深的节点的左子树都有变化,因此每个坐标空间的值与左祖先的距离有所不同。 为了将这些相对距离转换为绝对位置,我们在两个坐标空间中累积一个运行总数。
要插入新的更改,我们对最接近我们正在替换的范围的现有更改进行splay。当我们在splay操作期间重新排列指针时,我们可以根据本地可用的信息更新到每个节点左侧祖先的距离。一旦下限和上限节点已经旋转到树的根部,它们之间的任何节点都将被我们插入的变化所包围,这意味着它们可以被删除。然后,我们插入新的更改,并将其与树的根节点下的一个或两个节点进行合并,具体取决于它是否与它们重叠。

对于我们的Patch结构,splaying不仅仅是保持树更加平衡的机制。 实际上,我们依赖于将节点移动到树的根部的能力,以便将新的变化接合到结构中。如果使用红黑树等更为严格的平衡数据结构,以这种方式将节点旋转到根部将会更加困难。
值得注意的是,在上面所有的例子中,我们都使用了标量值来表示位置和距离。实际上,这些值被表示为由行和列组成的2维向量。这增加了一些复杂性,但基本的想法保持不变。值得注意的是,这个结构在本文描述的缓冲表示之外还有其他用处。我们最初创建它是为了汇总每个事务中发生的所有更改,因此我们可以通过diff来通知change listeners,并将最其存储在UNDO堆栈中。我们还使用Patch来指示缓冲区和屏幕坐标之间的转换,如面向展示的转换(如代码折叠)。这是一段复杂的代码,但是我们从中得到了很多。
一些最初的优化
将我们的缓冲区实现移到C++本身就Atom的整体效率而言是一个胜利。JavaScript可以相当快,但从根本上说,它是一种脚本语言,带有不可避免的开销。通过在C++中实现缓冲区,我们消除了JS的开销,并获得了最大化效率所需的控制。我们还通过简化堆并在热代码路径上分配更少的短暂对象来缓解V8垃圾收集器的压力。但是这些改进只是开始。这种新表现的真正价值在于其分层设计所带来的优化。
异步保存
在1.19之前,在Atom中保存缓冲区是一个同步操作。这是因为用于编写文件的代码是在Electron产生之前就存在了,那时在基于浏览器的桌面应用程序中执行异步I/O并不像现在这样容易。令人高兴的是,这个新的缓冲区实现为我们提供了一个以优雅的方式最终解决这个问题的机会。将缓冲区的内容从UTF-16转换为用户所需的编码并将其写入磁盘现在完全由C++在后台线程上执行。在开始保存之前,我们创建了一个快照,以便用户可以自由地进行额外的更改,即使在保存速度较慢时(例如使用网络驱动器时)也是如此。
autocomplete的同时在后台进行子序列匹配
默认情况下,Atom的自动完成系统根据光标前面的字符,从打开的缓冲区中选出相匹配的子序列作为建议单词。例如,bna| 会产生banana,bandaid和bandana作为建议。然后,根据匹配质量的指数来建议。
在Atom 1.22之前,我们通过为每个缓冲区维护一个唯一的单词列表,并在主线程上运行JavaScript来匹配,评分和排序建议来实现此功能。虽然这对大多数文件工作正常,随着文件大小的增加,单词列表开始消耗内存严重,主线程上的匹配建议可能会明显阻塞用户界面。
得益于新的缓冲区实现,我们在Atom 1.22后面推出了一个新的自动完成提供程序,它利用快照执行相同的工作,无需内存开销,并且不会对Atom的响应性构成威胁。现在大部分繁重的工作都是在一个新的TextBuffer.findWordsWithSubsequence方法中执行的,它在后台线程中执行匹配,评分和排序。这意味着我们可以在每次击键之后立即开始搜索建议,而其他工作则在主线程上进行。到下一帧画的时候,自动补全的建议通常是可用的,但搜索永远不会延迟帧的渲染。在罕见的情况下,搜索补全建议需要花费的时间超过一帧,我们只会在后续的帧中渲染它们。
未来的回报
这个新的缓冲区实现为将来的许多改进奠定了基础。近期,在工作线程中执行非阻塞读取的能力将帮助我们改进许多领域的响应能力,其中许多领域我们还尚未探索。
从长远来看,将我们的缓冲区实现切换到C++也为移植其他子系统打开了大门。我们正在逐步构建一个名为superstring的本地库,它在Atom的核心实现了多个性能关键组件,就像本文中的数据结构一样。我们通过V8 enbedding API 使用JavaScript与这个库进行交互,但是它也有工作Emscripten绑定在Electron之外使用。 现在,与缓冲区相关的临界状态已经进入"超字符串",我们可以递增地移植任何需要访问缓冲区内容的关键性能代码路径。
要明确的是,JavaScript的易用性和灵活性是一项巨大的资产,所以在用C++的原始性能与之交换之前,我们总是会三思而后行。
原文链接:http://blog.atom.io/2017/10/12/atoms-new-buffer-implementation.html
·END·
觉得本文有帮助?请分享给更多人
欢迎登陆Enterprise号#立刻扫码关注
